Kaveri Test: AMD A10-7850K und A10-7700K (5/10)
HSA Features mit hQ und hUMA - Teil 2
Grundlegende Notwendigkeit für das Big Data Beispiel sind Data Pointer. Diese sind sozusagen "Wegweiser", die CPUs durch Datenstrukturen lotsen. Bei den bislang nötigen Kopiervorgängen zwischen Arbeitsspeicher und GPU-Speicher wird eine Datenstruktur aber nicht nur kopiert, sondern beim Transfer in den Speicher der GPU auch serialisiert (= "übersetzt"), weil GPUs nicht mit Pointern der CPUs umgehen können. Dieses Abbild in ihrem eigenen Speicher wird dann von der GPU bearbeitet, das Ergebnis gespeichert und wiederum Deserialisiert (= "zurückübersetzt"). Das bedeutet hohen Programmieraufwand, denn neben der Erzeugung des Abbildes musste bisher häufig die originale Datenstruktur auch im Arbeitsspeicher erhalten bleiben, weil GPUs (abgesehen von Ausnahmen wie AMDs GCN-Architektur) nicht mit Page Faults umgehen können, die dann entstehen, wenn Quelldaten z.B. ausgelagert werden, während die GPU an ihrem Abbild arbeitet.
Mittels hUMA können nun CPU und GPU die Data Pointer einfach austauschen, da sie ohnehin Zugriff auf selben Speicheradressraum haben. Die Serialisierung entfällt, weil Daten nicht mehr kopiert werden müssen.
Für Anwendungsentwickler ist das praktisch, weil es ihnen Programmieraufwand erspart. Der Code wird schlanker und ist damit weniger anfällig für Fehler. Gleichzeitig sinkt die Hürde, für heterogene Systeme zu programmieren. AMDs Zielsetzung für die Zukunft lautet, dass mittels HSA das Programmieren für heterogene Plattformen so einfach und intuitiv erfolgen soll, wie es das heute für x86 Prozessoren ist.
Platform Atomics
Die Problematik des Serialisierens respektive Deserialisierens beudeutet auch, dass CPU und GPU bislang nicht parallel am selben Problem arbeiten konnten. Die CPU konnte Berechnungen zwar an die GPU auslagern, sich aber an deren Berechnugen nicht beteiligen. Diese Barriere ist aber auch recht nützlich, solange CPU und GPU keine Platform Atomics beherrschen.
Durch die HSA-Features der "Kaveri"-APUs wird exakt das möglich. Sie beherrschen Platform Atomics, die dafür sorgen, dass es zu keinem Data Race kommt. Ein Data Race entsteht, wenn CPU und GPU an der selben Datenstruktur arbeiten, sie also durch das Lesen und Schreiben von Werten so manipulieren, dass ein ungültiges Ergebnis entsteht. Sehr vereinfacht tritt ein Data Race dann auf, wenn beispielsweise die CPU basierend auf einem Wert arbeitet, der durch ein Ergebnis der GPU zwischenzeitlich bereits verändert wurde. Das Ergebnis der CPU ist dann falsch.
Die gegenseitige Ergänzung der HSA (Platform Atomics) und OpenCL 2.0 (C11 Atomics) Spezifikationen vermeidet Data Races, weil die jeweiligen Cores sich gegenseitig auf erfolgte Änderungen aufmerksam machen. Aus diesem Grund können die CPU Cores und CPU Cores simultan an der selben Datenstruktur arbeiten, ohne dass es zu einem Data Race kommt. Diesem Umstand trägt AMDs Bezeichnung als Compute Cores Rechnung.
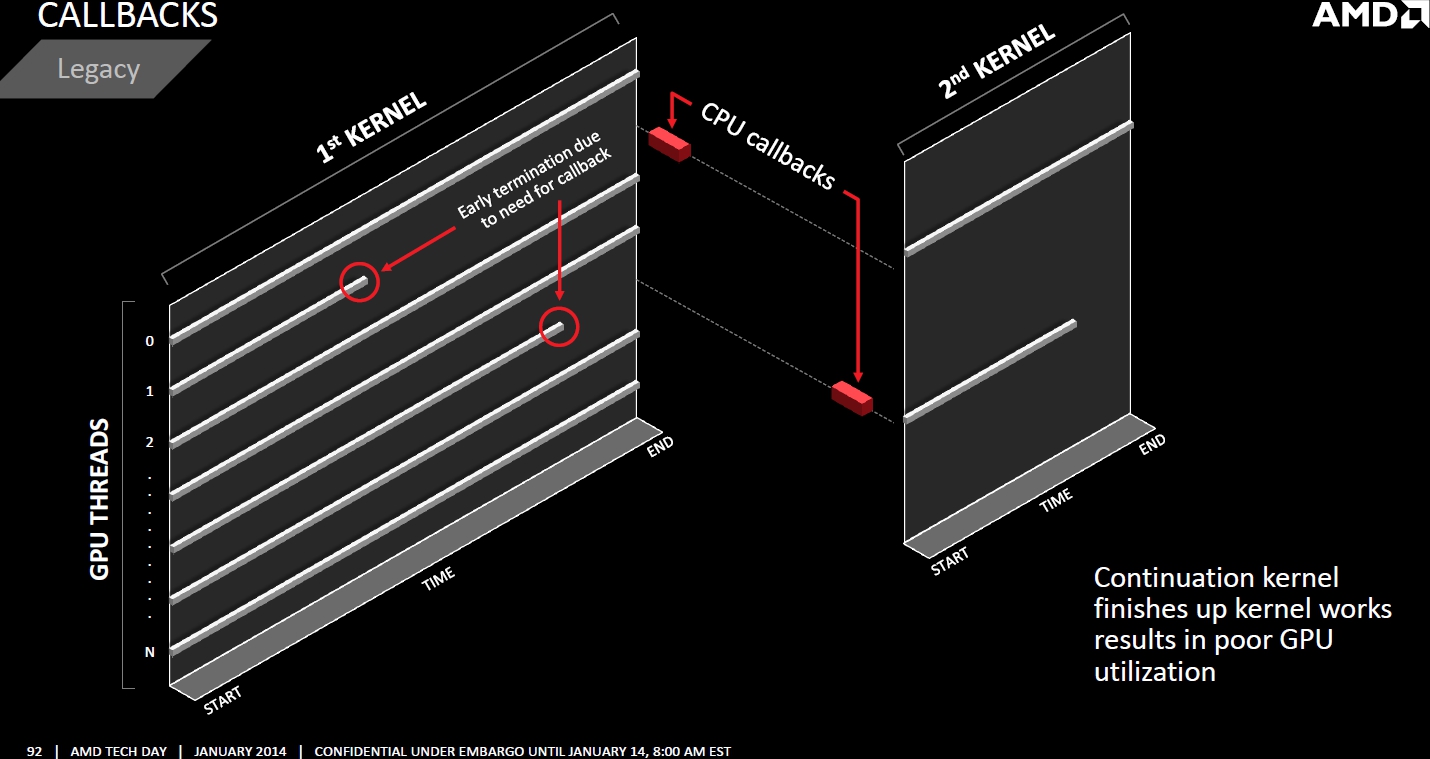
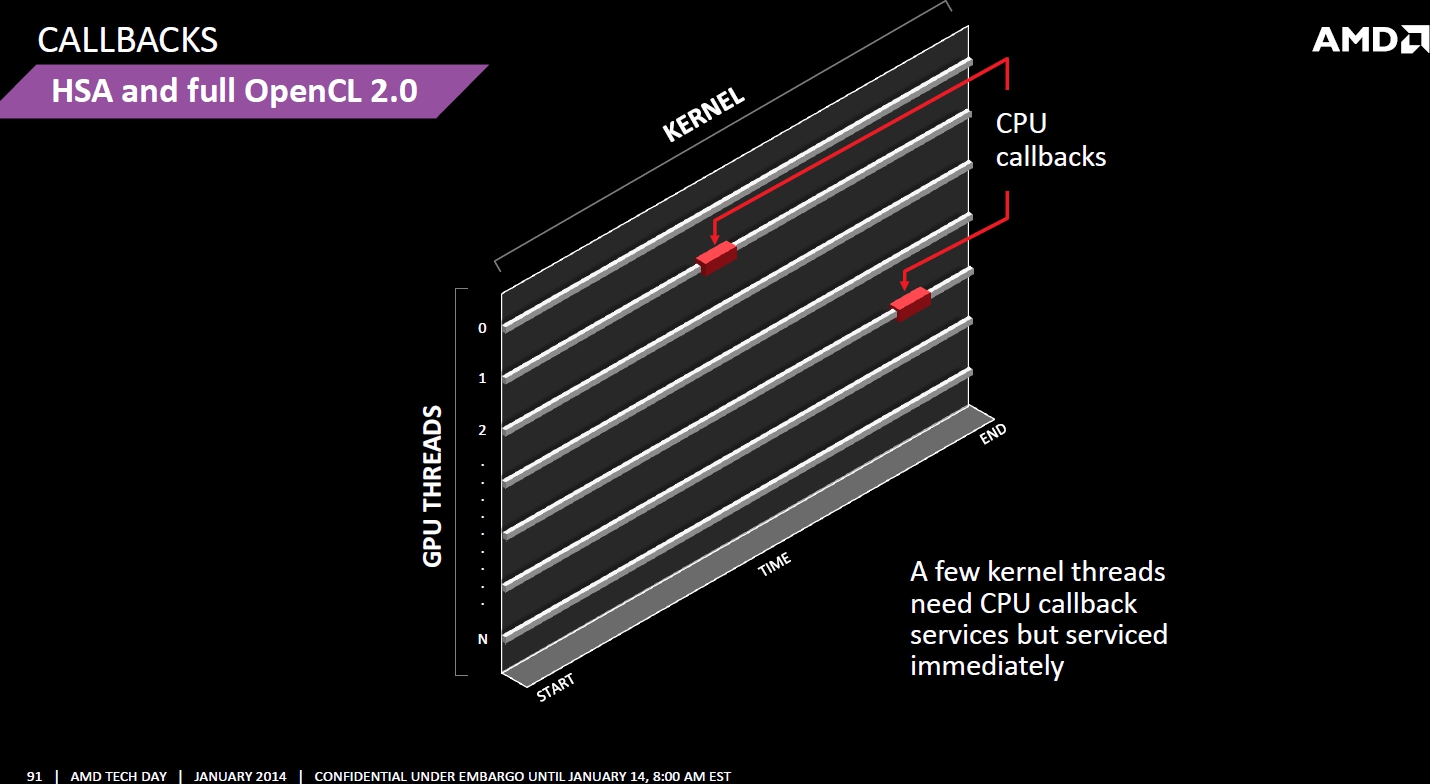
CPU Callbacks
Für Performanceverlust sorgen bei Compute-Berechnungen bislang auch CPU Callbacks. Ein solcher wird zum Beispiel nötig, wenn die GPU im Zuge ihrer Berechnugnen auf Daten zurückgreifen muss, die nicht in ihren Speicher kopiert wurden. Sie muss dann ihre Arbeit unterbrechen, die CPU um Nachlieferung der fraglichen Daten ersuchen und kann erst nach dem Kopiervorgang die Arbeit fortsetzen.
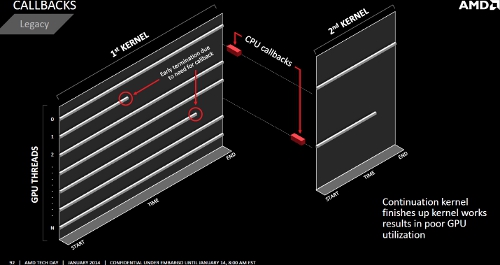
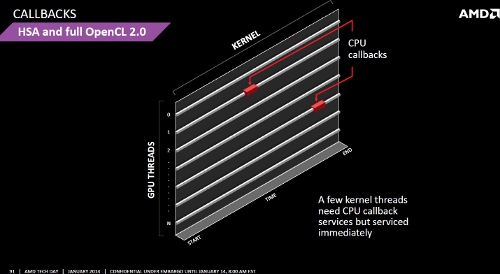
Mithilfe der Data Pointer und Platform Atomics können sich die GPU Cores der "Kaveri"-APUs jene Daten, welche sie benötigen, einfach direkt selbst einholen. Dies verbessert vor allem die effiziente Auslastung der GPU Compute Units.



 Zurück:
Zurück:  Weiter:
Weiter: